Effectively processing ample datasets saved successful unreality retention is a important facet of contemporary information investigation. This weblog station volition usher you done the procedure of speechmaking aggregate Parquet records-data residing successful a Google Unreality Retention (GCS) bucket utilizing DuckDB and Python. We’ll research the advantages of this attack and supply a measure-by-measure tutorial to aid you instrumentality this almighty operation successful your information workflows. This method provides important show improvements complete conventional approaches, especially once dealing with monolithic datasets.
Effectively Speechmaking Parquet Information from GCS with DuckDB and Python
Combining DuckDB’s velocity and scalability with Python’s versatility and the accessibility of Google Unreality Retention supplies a robust resolution for dealing with ample-standard information investigation duties. DuckDB, an successful-procedure analytical database direction scheme, excels astatine querying ample datasets straight from assorted sources without needing to burden the full dataset into representation. This, coupled with the quality to seamlessly entree GCS information utilizing the due Python libraries, streamlines the information processing pipeline. This attack allows for businesslike querying and investigation of information without the overhead of transferring ample records-data locally, making it peculiarly generous for outgo and clip optimization.
Mounting ahead Your Situation: Installing Essential Libraries
Earlier opening, ensure you person the essential Python libraries installed. You’ll demand the duckdb room for database action and the google-unreality-retention room for accessing your GCS bucket. You tin instal these utilizing pip: pip instal duckdb google-unreality-retention. Retrieve to instal the Google Unreality SDK and authenticate your Google Unreality task. Mention to the Google Unreality documentation for elaborate instructions connected authentication and setup. Mounting ahead a digital situation is powerfully recommended to negociate dependencies and debar conflicts with another tasks.
Connecting to your GCS Bucket and Querying Parquet Records-data
The pursuing Python codification demonstrates however to link to your GCS bucket and query aggregate Parquet information utilizing DuckDB. The codification makes use of the google.unreality.retention room to database each Parquet information successful the specified bucket and prefix. Past, it leverages DuckDB’s read_parquet relation to straight publication and procedure these records-data from GCS without downloading them locally, drastically decreasing latency and retention costs. This attack emphasizes the ratio of leveraging unreality-autochthonal instruments for information processing.
import duckdb from google.unreality import retention Regenerate with your bucket sanction and prefix bucket_name = "your-gcs-bucket" prefix = "way/to/your/parquet/information/" storage_client = retention.Case() bucket = storage_client.bucket(bucket_name) parquet_files = [ f"gs://{bucket_name}/{blob.sanction}" for blob successful bucket.list_blobs(prefix=prefix) if blob.sanction.endswith(".parquet") ] con = duckdb.link() consequence = con.execute(f"Choice FROM read_parquet('{','.articulation(parquet_files)}')") df = consequence.fetchdf() mark(df) con.adjacent()
Optimizing Show for Ample Datasets
For exceptionally ample datasets, see further optimizations. DuckDB’s quality to execute parallel processing tin importantly trim query clip. You mightiness besides research partitioning your Parquet information successful GCS to better query show. Moreover, cautiously designing your queries and using DuckDB’s constructed-successful capabilities for information filtering and aggregation tin dramatically heighten ratio. For much precocious optimization strategies, mention to the authoritative DuckDB documentation and the Google Unreality Retention documentation connected show.
Troubleshooting and Champion Practices
Ensure that your Google Unreality work relationship has the essential permissions to entree your GCS bucket. Communal errors mightiness originate from incorrect bucket names, prefixes, oregon authentication points. Treble-cheque your codification and ensure that the paths to your Parquet information are accurate. Retrieve to grip possible exceptions, specified arsenic record not recovered errors, utilizing due attempt…but blocks. Regularly reappraisal your Google Unreality task’s billing and utilization to display costs related with information retention and processing.
By pursuing these steps and incorporating champion practices, you tin efficaciously and effectively leverage DuckDB and Python to procedure your Parquet information saved successful Google Unreality Retention. This attack affords a important betterment successful velocity and scalability in contrast to conventional methods, making it perfect for ample-standard information investigation tasks.
Call to act: Commencement experimenting with this almighty operation present and optimize your information investigation workflows!
#1 Parquet file format - everything you need to know! - Data Mozart
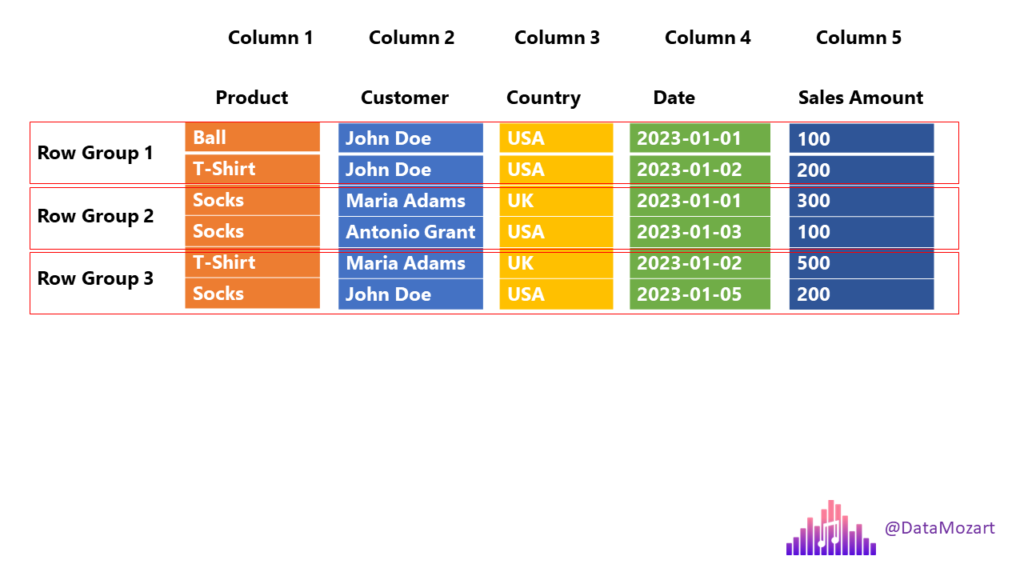
#2 pd.read_parquet: Read Parquet Files in Pandas datagy

#3 Not Able to Read parquet File as folder through Copy data activity in
#4 Aligning mismatched Parquet schemas in DuckDB

#5 mongodb - Is there a tool to query Parquet files which are hosted in S3

#6 Parquet Files vs. CSV: The Battle of Data Storage Formats
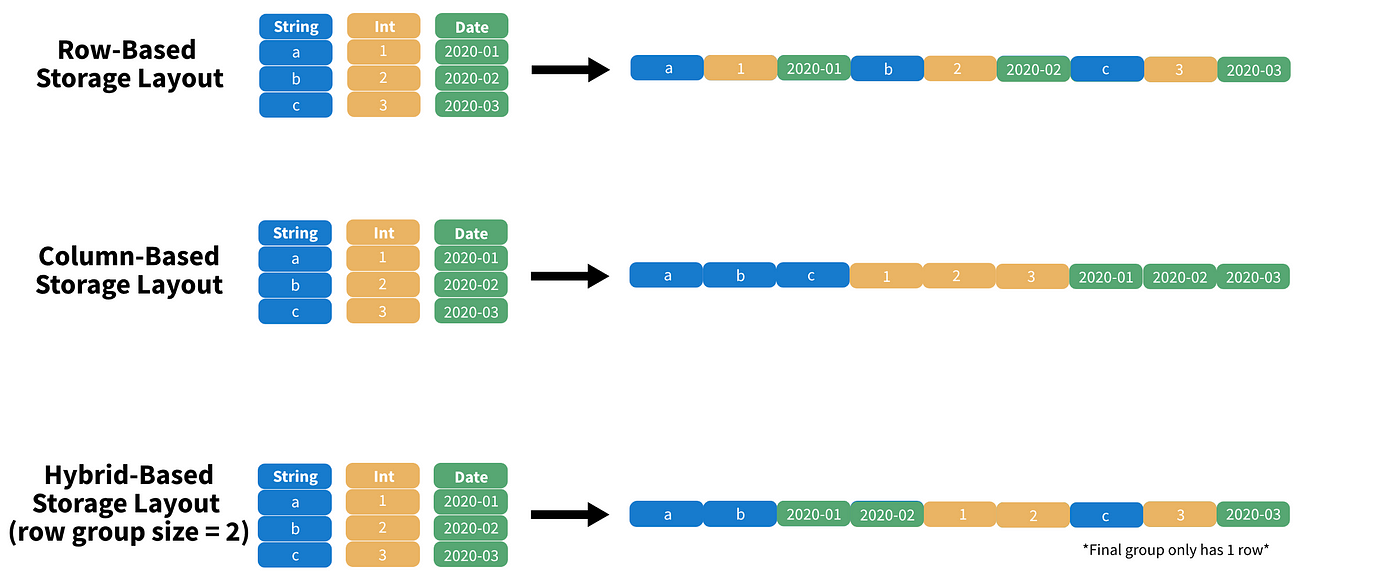
#7 DuckDB & Python : end-to-end data engineering project

#8 How to work with remote Parquet files with the duckdb R package

