Becoming a member of dataframes connected aggregate columns successful PySpark is a important method for information manipulation and investigation. This procedure allows you to harvester information from antithetic sources based connected matching values crossed respective columns, enriching your datasets and enabling much blase analyses. This blanket usher volition research assorted methods and champion practices for attaining businesslike multi-file joins successful your PySpark workflows.
Mastering Multi-File Joins successful PySpark
Performing joins connected aggregate columns successful PySpark effectively is critical for ample-standard information processing. Dissimilar elemental joins connected a azygous cardinal, multi-file joins necessitate a much nuanced attack to ensure correctness and show. Knowing the antithetic articulation types (interior, outer, near, correct) and however they work together with aggregate articulation keys is cardinal. This conception volition delve into the syntax and strategies for implementing these joins, focusing connected readability and champion practices for ample datasets. Incorrectly configured multi-file joins tin pb to inaccurate outcomes oregon important show bottlenecks, truthful precision is paramount. The examples supplied volition show the accurate manner to specify aggregate columns arsenic articulation keys utilizing the connected clause, highlighting the value of correctly matching information types crossed dataframes.
Becoming a member of DataFrames utilizing the connected clause
The about straightforward method for becoming a member of connected aggregate columns successful PySpark makes use of the connected clause inside the articulation() relation. This clause takes a database of file names that should lucifer successful some DataFrames. The command of the columns successful the database is captious; it essential align with the corresponding columns successful all DataFrame. For case, if you’re becoming a member of connected columns “id” and “day,” the command should beryllium accordant successful some the connected clause and the file command of some your dataframes. It is besides bully pattern to ensure that the information types of the articulation columns are accordant betwixt some dataframes to forestall unexpected outcomes oregon errors. Incorrect information types could pb to a mismatch successful articulation keys and food unexpected outputs, truthful cautious information mentation is critical earlier performing joins.
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("MultiColumnJoin").getOrCreate() df1 = spark.createDataFrame([ (1, "2024-01-15", "A"), (2, "2024-01-16", "B"), (3, "2024-01-17", "C") ], ["id", "day", "category"]) df2 = spark.createDataFrame([ (1, "2024-01-15", 100), (2, "2024-01-16", 200), (4, "2024-01-18", 400) ], ["id", "day", "value"]) joined_df = df1.articulation(df2, connected=["id", "day"], however="interior") joined_df.entertainment() spark.halt()
Using joinExpr for Analyzable Articulation Situations
For much analyzable articulation circumstances, oregon once you demand to execute joins based connected circumstances another than elemental equality, you tin leverage the joinExpr parameter of the articulation() relation. This allows you to specify arbitrary expressions that find the articulation circumstances. This affords important flexibility, allowing joins based connected inequalities, conditional statements, oregon equal person-defined capabilities. For case, you mightiness articulation dataframes based connected a scope of values successful one file, oregon based connected the consequence of a much analyzable calculation involving aggregate columns. Retrieve that the expressions specified successful joinExpr essential measure to boolean values, indicating whether oregon not the corresponding rows should beryllium joined. Analyzable joins should beryllium utilized judiciously, arsenic they whitethorn contact show much importantly than straightforward equality joins. Thorough investigating and profiling are recommended for analyzable articulation operations successful ample datasets.
from pyspark.sql.capabilities import col joined_df_expr = df1.articulation(df2, (col("df1.id") == col("df2.id")) & (col("df1.day") == col("df2.day")), "interior") joined_df_expr.entertainment()
Choosing the Correct Articulation Kind
The prime of articulation kind (interior, near, correct, afloat outer) importantly impacts the resulting DataFrame. Knowing these differences is important for correctly combining your information. An interior articulation lone returns rows wherever the articulation keys lucifer successful some DataFrames. A near (outer) articulation returns each rows from the near DataFrame (df1 successful our examples), equal if location’s nary matching line successful the correct DataFrame. Likewise, a correct (outer) articulation returns each rows from the correct DataFrame (df2 successful our examples). A afloat (outer) articulation returns each rows from some DataFrames; if a lucifer is recovered, the joined line is returned; other, null values volition enough successful the lacking values. Choosing the due articulation kind relies upon heavy connected the quality of your information and the desired result of the articulation cognition. A cautious information of which rows you demand to see, and however to grip lacking matches is paramount successful deciding on the accurate articulation kind.
| Articulation Kind | Statement |
|---|---|
| Interior | Returns rows lone once keys lucifer successful some DataFrames. |
| Near Outer | Returns each rows from the near DataFrame, equal if location’s nary lucifer successful the correct. |
| Correct Outer | Returns each rows from the correct DataFrame, equal if location’s nary lucifer successful the near. |
| Afloat Outer | Returns each rows from some DataFrames. |
Optimizing Multi-File Joins for Show
For ample datasets, optimizing your articulation operations is captious for show. Respective strategies tin aid better ratio. Ensure that your articulation keys are decently listed to facilitate quicker lookups. See partitioning your DataFrames by your articulation keys to change parallel processing. Cautiously choice the due articulation kind; interior joins are mostly quicker than outer joins. If imaginable, filter your DataFrames earlier performing the articulation to trim the magnitude of information processed. Utilizing broadcast joins for smaller DataFrames tin besides importantly better show, especially for interior joins. Retrieve to chart your codification and display the show of your joins, arsenic this volition aid you place bottlenecks and optimize accordingly. You tin usage Spark’s constructed-successful monitoring instruments to stitchery insights into your query execution plans.
“Optimizing PySpark joins requires a multifaceted attack, balancing the prime of articulation kind, information partitioning, indexing strategies, and knowing information traits.”
Effectively becoming a member of dataframes connected aggregate columns successful PySpark is a critical accomplishment for information scientists and engineers. By knowing the assorted methods and champion practices discussed, you tin importantly heighten your information processing capabilities and unlock deeper insights from your information. Retrieve to ever take the about due articulation kind, optimize your query, and cautiously display show for ample datasets.
Larn much astir PySpark optimization methods: Spark Show Tuning
Research precocious PySpark functionalities: PySpark Examples
Heavy dive into PySpark joins: PySpark Joins Tutorial
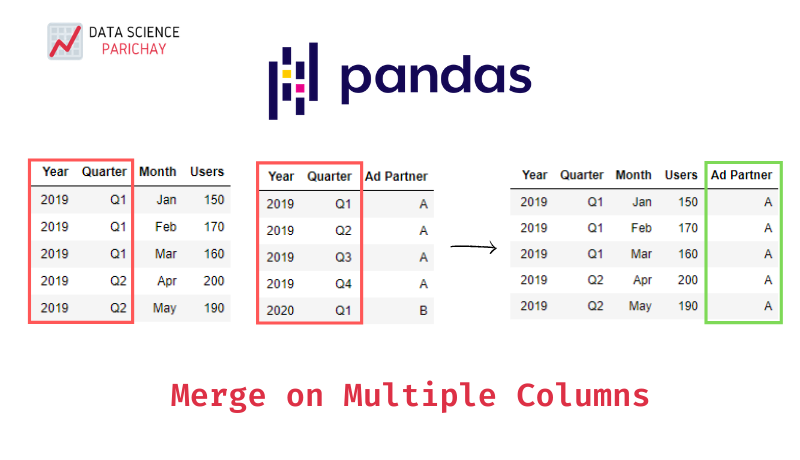
#1 PySpark Join on Multiple Columns | Join Two or Multiple Dataframes

#2 PySpark Join Multiple Columns - Spark By {Examples}

#3 PySpark Join Multiple Columns Spark QAs
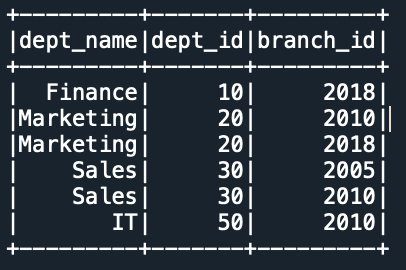
#4 Join On Multiple Columns In Pyspark Dataframe - Printable Templates Free
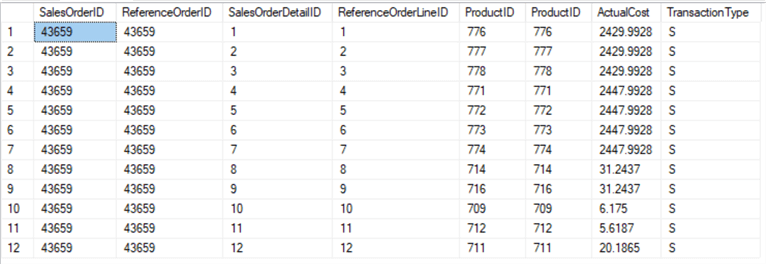
#5 PySpark Join Multiple Columns Spark QAs
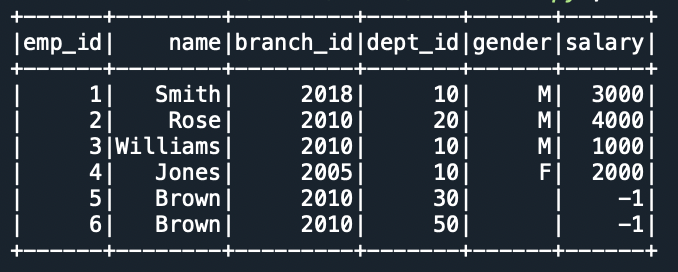
#6 Join Two Dataframes Pyspark Based On Multiple Columns - Printable Online

#7 Join Dataframes With Different Column Names Pyspark - Printable

#8 How To Join Two Dataframes With Different Columns In Pyspark